
When modernising legacy systems, a key issue is figuring out how to migrate your existing data into a database that has been remade from the ground up. Rewriting outdated applications from scratch usually means a brand-new schema that can look unrecognisable next to the old one. Transferring the existing dataset into your new system is a challenge that requires rigorous planning, development, and testing.
This blog post draws on our team’s learnings from one of our recent projects: a fully modernised and cloud-native rewrite of a document storage portal that serves over 100 health organisations. The application makes 80,000+ active documents accessible to hospital staff around the clock, meaning zero downtime. We will use these experiences to highlight some of the important considerations when designing a new schema and planning a data migration into AWS Aurora. We will also cover the design principles used in our migration tool, and some recommendations on how to architect a cloud-native solution to orchestrate the process.
Architecting the data
Migrating data from one database to another can vary in difficulty depending on your situation. For homogeneous or heterogeneous migrations with relatively simple schema changes and little to no complex business logic, AWS Database Migration Service (DMS) is a fantastic choice. It makes the entire process straightforward and can continuously replicate changes to the source database to keep the target up to date. For more complex migrations however, custom tools are required.
During our rewrite project, data migration considerations were not a part of the initial planning when designing the new application – this was a conscious decision. We were 100% focused on creating a solution that fit the business requirements as best as possible, including architecting a brand-new schema for the application’s data. It wasn’t until much later that we planned out how we would transform all the data in the legacy application to fit the new mould we had created. Having developers that are external to the data architecture process try to map one schema to another is inefficient. So even though the migration process does not need to happen until the very end of the project, you will save a lot of time by creating your migration plan from the outset. This means mapping every single column and foreign key in your new schema to one in the legacy application and updating these mappings every time a change is made in the rewritten application. It’s important to note here that if you will be needing to perform a heterogeneous migration – that is from one database management system to another (e.g. SQL Server to Aurora MySQL) – it is important to also record the different data types used in each database.
You may choose not to copy primary key values during your migration process for several reasons. In this case, you will need to set up mapping tables in an intermediary database that records links between entities’ IDs in the legacy system and their IDs in the new system. This is important not just to keep track of which rows have been migrated, but also to maintain links between entities joined by foreign keys. A mapping table will need to be added to the migration plan for each entity that does not set its primary key value from the legacy database.
Writing a migration tool
So, you have a fully-fledged plan that details how to map data from your legacy database into your rewrite database. How do you use this plan to execute a successful data migration? To do that, you’re going to need a tool with all your mappings and custom business logic built in. The high-level implementation is simple: connect to the legacy database, extract its data, transform it, and save it to the new database. However, writing this application in a maintainable and extendable way is key.
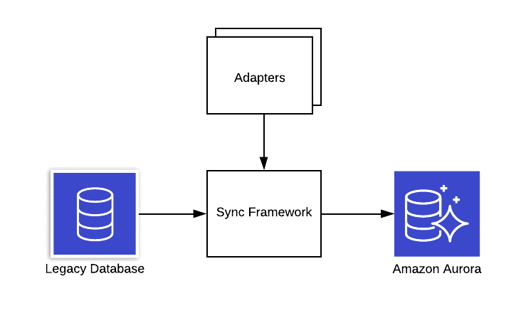
Adapters
In our project, we used adapters to handle the migration and synchronisation of self-contained chunks of data. These are often associated with a single table, though occasionally an adapter may be responsible for multiple tables or may perform some secondary business logic. For example, one of our adapters was responsible for processing users with duplicated email addresses – a state which was allowed in the legacy system but restricted in the new system. The important thing is that each adapter handles one distinct portion of the dataset.
The primary benefit of utilising adapters in the structure of the migration tool is the separation of responsibility. This keeps application requirements manageable as the migration process is organised into logical parts. The team can work on adapters individually, which makes development more efficient as each team member has a narrower focus and can gain a deeper understanding of what exactly the job of their adapter is. This pattern also allows for more refined testing as the adapters can be run one-at-a-time for unit tests or integration tests.
The first function of an adapter is initial migration. This is what happens during the initial first run of the tool. It performs a wholesale copy of the data into the new application using the rules defined in the migration plan. This includes modifying data types, transforming values and conditionally ignoring certain entities according to required business logic. Importantly, the adapter will also record mappings between the legacy table and the new table.
Adapters will also consume these mappings when determining foreign key connections between tables. For example, say a department belongs to an organisation and is linked via an organisation ID. When migrating the department entity to the new system, the department adapter will need to look up the ID of the linked organisation entity in the mapping table. This means that the order in which the adapters run is important, as migrating data may have missing or outdated information if they are dependent on adapters that have not yet run.
The second function of an adapter is ongoing synchronisation. Under our design principles, our tool was designed to be run intermittently – i.e. without continuous replication. The reasoning for this was simply that it is easier to write a migration tool that can run as needed to update the target database at any given time, rather than attach to the legacy database and copy all changes as they come in. We also had the conditions to allow for this approach as the load on the database was very low outside business hours, and there was no requirement for the new system to be usable at the same time as the legacy system on a user-by-user basis. This meant that synchronising data with this pattern is just a matter of migrating new entities and overwriting existing entities by looking up their mappings and setting their values from the legacy system.
The Sync Framework
The final step in the tool is running all the adapters. For each adapter, the tool should extract the data from the legacy database, and then use the associated mappings to determine whether to insert or update the entities in the new system. We called this the Sync Framework. In our tool, we used dependency injection to register the adapters in a specific order and then provide them in a controller which handled the processing of the data. The framework also handles special cases such as different types of adapters. One example from our tool is the concept of a disabling adapter, which was a special kind of adapter that handled entities which were deleted from the legacy system.
In large applications with similarly large datasets, performance of the migration tool is a very important consideration. A migration could end up processing hundreds of millions of rows, so every optimisation counts. One of the primary jobs of the sync framework is extracting and loading data to and from the legacy and rewrite databases. Utilising a buffer when extracting data proved to be extremely useful in our project in terms of performance. Other small optimisations such as using a StringBuilder for string manipulation can save large amounts of time. Mapping tables can also be leveraged to improve performance by pre-processing data dependencies. This was useful when we needed to pre-process XML blobs stored in a database table to extract GUIDs referenced in another table.
The sync framework is also the place for other orchestration logic. An important part of this is using the mapping tables to determine whether a given row in the source database has been previously migrated, or possibly deleted. This will allow you to decide whether to create a new entity or update an existing one. Data migrations can also take a long time, with many connections to both the source and target databases required. The risk of a transport-level error occurring is high, so adding automatic retry functionality is recommended. Further functionality that should be added to the sync framework includes error-handling, data consistency checks, application logging, and alert systems.
Now that you’ve written the migration tool, it’s time to get it running in the cloud. Before we go running it in production however, it pays to test it out first. Hopefully your newly rewritten application uses Infrastructure as Code with CloudFormation (or the cutting-edge AWS CDK – if you haven’t used it we highly recommend it). Deploying a new environment to test out your migration tool will allow you to not only find and fix any issues with the schema mapping logic that may have been missed or changed during development, but also provides a space to continue testing ongoing synchronisation once the production version of your application goes live.
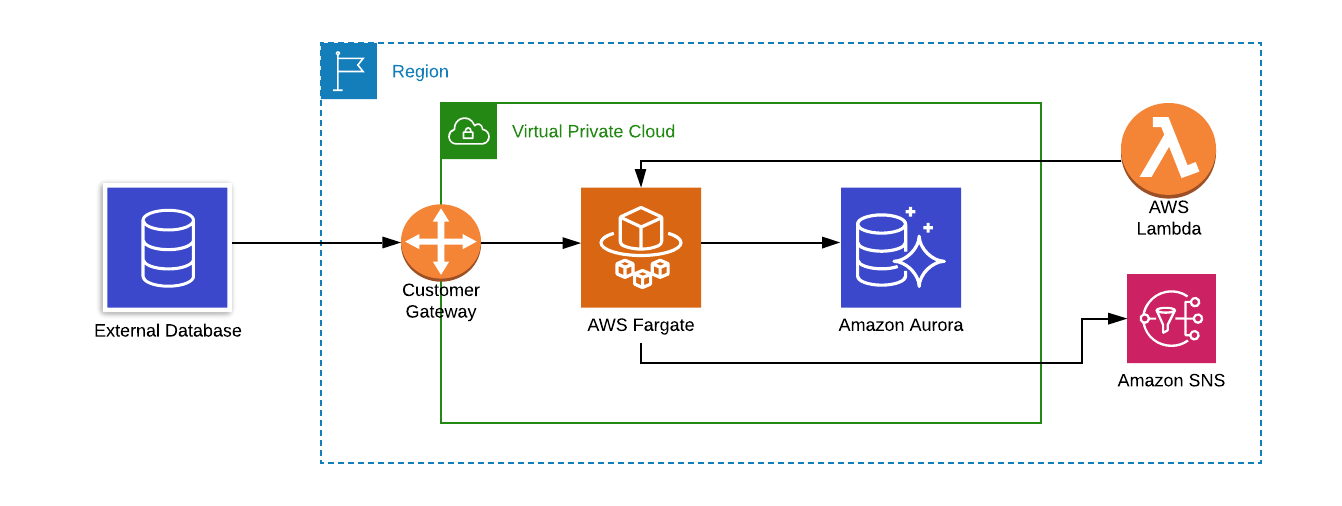
The tool will need to run somewhere that has access to both your legacy database and your new AWS Aurora database. Unless both databases are in the same VPC, it’s likely you will need to set up a VPN. If your legacy database is already in AWS, this is as simple as setting up a VPC Link from the legacy VPC to the VPC in your new environment. If not, you will need to open an IPsec VPN tunnel to your external environment, which can be achieved using a Customer Gateway. You will also need to create a security group with ingress to your AWS Aurora instance.
The best way to run your migration tool is in a Docker container using AWS Fargate. It’s capable of handling the compute processing and network throughput required to migrate the data, without having to worry about managing an EC2 instance. The Fargate task can be started by Lambda, which can be triggered by many services. In our project, we run a nightly sync using the tool at 4am – the time with the lowest load on the databases. If you want to run the tool on a schedule, then a CloudWatch Events rule can trigger the workflow when required.
To ensure recoverability in the event of a critical migration failure, it is important to back up the AWS Aurora database before running the tool. Upon triggering the workflow, Lambda can create a manual DB snapshot of the instance. Because this is an asynchronous process, we can then use Amazon RDS Event Notifications to trigger the next step in the workflow. When the snapshot is complete, a notification is sent out, which can then run our Lambda function that starts the migration Fargate task.
For alerts and monitoring, Amazon SNS is the best way to notify the appropriate people when a migration succeeds – or fails. Topics can be created to alert key personnel if there has been an internal error in the tool, or something external like an unreachable database. Logs and exception details can be passed on to developers who can analyse what happened in a code failure. This is important as your data migration may go on for a long time, or it may run overnight, so having the correct people get notified allows for a fast response.
Summary
More and more businesses are looking to modernise their legacy applications and bring them to the cloud. Being able to plan and execute a successful data migration into AWS Aurora is one of the most important parts of that process. With deliberate planning from the beginning of your data architecture, a maintainable and extendable migration tool, and a resilient cloud-native architecture in which to run it, you’re sure to get all of your data where it needs to be without a hitch.
If you would like to find out more about migrating legacy applications, get in touch with our team to discuss how we can help by emailing info@lancom.co.nz.



